
Contrastive Decoding: Open-ended Text Generation as Optimization
Published:
The paper proposes a new decoding method for open-ended text generation, called contrastive decoding (CD), which aims to generate text that is fluent, coherent, and informative, by exploiting the contrasts between expert model and amateur model behaviors.

Abstract
- The paper proposes a new decoding method for open-ended text generation, called contrastive decoding (CD).
- CD measures the difference between the log-probabilities of a large model (expert) and a small model (amateur), subject to a plausibility constraint that filters out low-probability tokens under the expert.
- CD aims to generate text that is fluent, coherent, and informative, by exploiting the contrasts between expert and amateur behaviors.
- CD requires no additional training and works across different model scales and domains.

Problem Statement
- Generated text from LLM is prone to incoherence and topic drift due to poor sampling choices over long sequences
- Maximizing probability in sequence often results in short, repetitive and tedious text
Solution
- Author proposes contrastive decoding (CD), which searches for text that maximizes the difference between expert log-probabilities and amateur log-probabilities, with restricted search space
- Why take the max difference between expert and amateur log-probabilities?
- Smaller LLM gives high probability to short, repetitive, irrelevant, uninteresting tokens
- Larger LLM gives high probability to desirable outputs
- Hence, by getting the max difference between expert and amateur model, we can improve text generation
- Advantage of CD:
- No training required, compared to unlikelihood training and contrastive learning proposed in other paper
Methodology
- Expert model gives high probability to good, non-repetitive tokens, whereas amateur model gives high probability to undesired tokens
- We want to reward text patterns favored by the expert LMs and penalizes patterns favored by the small amateur LMs. Therefore, the author proposed Contrastive objective, $L_{CD}(x_{\text{cont}}, x_{\text{pre}})$:
- If tokens from small LMs not favorable, why don’t we penalize amateur LMs completely?
- Small LMs still capture simple aspects of English grammar and common sense
- The author introduced plausibility constraint to complement CD objective
Adaptive Plausibility Constraint
\[V_{\text{head}}(x_{<i}) = \{x_i \in V : p_{\text{EXP}}(x_i | x_{<i}) \geq \alpha \max_{w} p_{\text{EXP}}(w|x_{<i})\}\]- The constraint only keeps tokens that have probability greater than or equal to a fraction α of the maximum probability token under the expert model
- $\alpha$ in the range of [0,1], it truncates next token distribution of $p_{EXP}$
- large $\alpha$, keep only tokens with high probabilities
- small $\alpha$, allows lower probabilities tokens to be considered
- $\alpha = 0.1$ is used in this paper.
- So, it only keeps 10% of the most likely token of the expert model
Full Method
\[\text{CD-score}(x_i; x_{<i}) = \begin{cases} \log \frac{p_{\text{EXP}}(x_i|x_{<i})}{p_{\text{AMA}}(x_i|x_{<i})}, & \text{if } x_i \in V_{\text{head}}(x_{<i}), \\-\infty, & \text{otherwise}.\end{cases}\]Choice of Amateur
We should select the amateur LM that downplays behaviors from the expert LM. Three aspects to consider:
- Scale: We prefer small scale LMs because they are more prone to errors
- Temperature: We prefer $\tau$ close to 0 because it highlights the mode of the amateur distribution, which is more prone to errors
- Context window: Short context length. To weaken the coherence of the amateur LMs
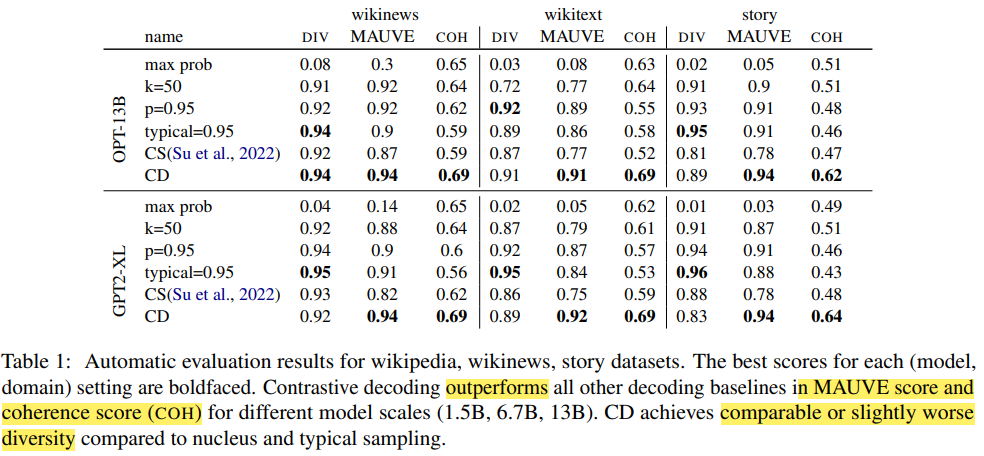
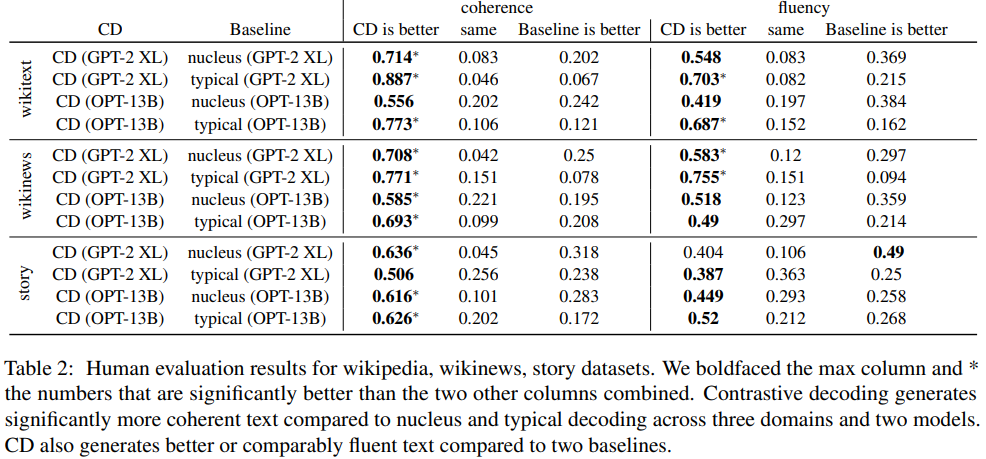
Results
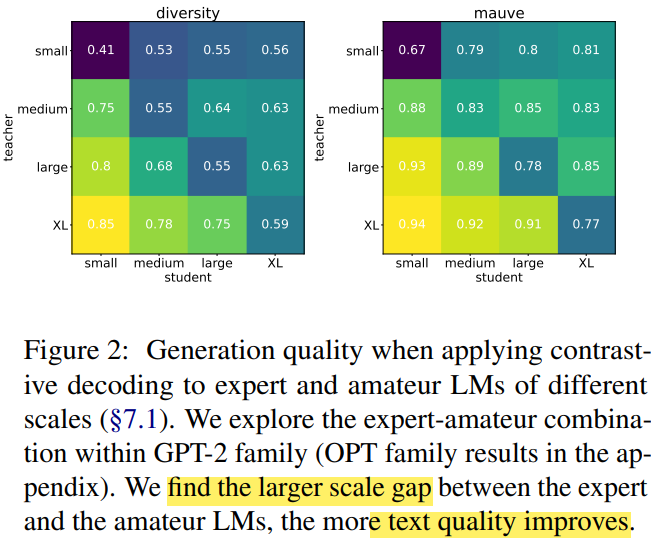
Generated text are more diverse and higher quality when using XL model size as teacher, small model size as student
Reference
- Li et al. “Contrastive Decoding: Open-ended Text Generation as Optimization”, ACL 2023