
Making Large Language Models Perform Better in Knowledge Graph Completion
Published:
This paper proposes knowledge prefix adapter (KoPA), an approach to improve structural-aware reasoning, thereby enhancing the reasoning ability of LLM.
Abstract
- The paper discusses how to make LLMs perform better in knowledge graph completion (KGC), which is a task to predict missing triples in knowledge graphs (KGs)
- The paper proposes a knowledge prefix adapter (KoPA), which uses structural embeddings of entities and relations in KGs to inform the LLMs of the KG structure and enable structural-aware reasoning.
Problem Statement
- Transforming KGC tasks into text-based prediction leads to some issues:
- inadequate memory for precise and nuanced factual knowledge (hallucination)
- Current KGC approach apply vanilla instruction tuning, which neglects the useful structural information
Introduction
- KGs form a semantic web containing extensive entities and relations, which model and store real-world knowledge in the triple form: (head entity, relation, tail entity)
- Manually edited or automatically extracted knowledge graphs are often incomplete, consisting only of observed knowledge and leaving many missing triples undiscovered. This motivates knowledge graph completion (KGC) to predict missing triples in a KG.
- Existing KGC approaches are divided into two categories: embedding-based methods and pre-train language models methods (PLM)
Notation & Preliminaries
- Denote KG, $G = (E, R, T, D)$ ,
- $E$ denotes entity set
- $R$ denotes relation set
- $T$ denotes the triple set of head entity, relation, tail entity
- $D$ denotes text description set of each entity and relation
- Denote LLM as $M$, the input textual sequence $S$ consists of
- the instruction prompt $I$
the triple prompt $X$:
\[X(h, r, t) = D(h) \oplus D(r) \oplus D(t)\]where $\oplus$ denotes the concatenation operation
- the optional auxiliary demonstration prompt $U$
- To investigate how LLM accomplish KGC task:
- In LLM paradigm, the model $M$ is expected to answer ‘true’ or ‘false’ given the textual sequence input $S = I ⊕ U ⊕ X$
Training-free Reasoning Approaches
Zero-shot reasoning approach
- The input sequence denoted as $S_{zsr} = I_{zsr} \oplus X$, without auxiliary information $U$
- The decoding process of LLM $M$ can be formulated as:
where $A_{zsr}$ is the generated answer
- In this setting, no KG information is added to $S$
In-context learning approach
- This approach is able to include auxiliary information $U$
- The decoding process of LLM $M$ can be formulated as:
where $A_{icl}$ is the generated answer
- $U$ is the demonstration triple $(h,r,t)$. The author proposed to sample triples that are in the local structure of $h$ and $t$. Both positive triples and negative triples are sampled together.
- Hence, we are able to incorporate the local structure information into $U$ with both positive and negative samples.
Instruction-tuning Approach
Vanilla instruction tuning
- $I_{it}$ describes the details of completing the triple classification task
- $X$ describes prompt of the triple
- The input to the model $M$:
where $A_{it}$ is the predicted answer of the training data
- The model $M$ is fine-tuned with the next word prediction task with the objective:
where $𝑠_𝑖$ $(𝑖 = 1, 2, . . . , |S_{𝑖𝑡}|)$ represents the textual tokens of the input sequence $S_{it}$
- Vanilla IT fine-tunes the $M$ to learn from a single triple, limiting its ability to utilize KG’s rich semantics
Structural-aware instruction tuning
- To incorporate the structural information, the neighborhood of head $ℎ$ and tail $t$ are sampled. Next, we put the textual descriptions of neighborhood triples in the demonstration prompt $U_{it}$
- Hence, the input training sequence is now $S_{𝑖𝑡} = I_{𝑖𝑡} ⊕U_{𝑖𝑡} ⊕X⊕A_{it}$
Methodology
Current approaches such as training-free reasoning approach and instruction-tuning approach has several drawbacks:
- invalid or redundant information
- not scalable and effective because of the lengthy prompt
Hence, this paper propose knowledge prefix adapter (KoPA) to leverages self-supervised structural embedding pre-training to capture the structural information in the KG.
Knowledge Prefix Adapter (KoPA)
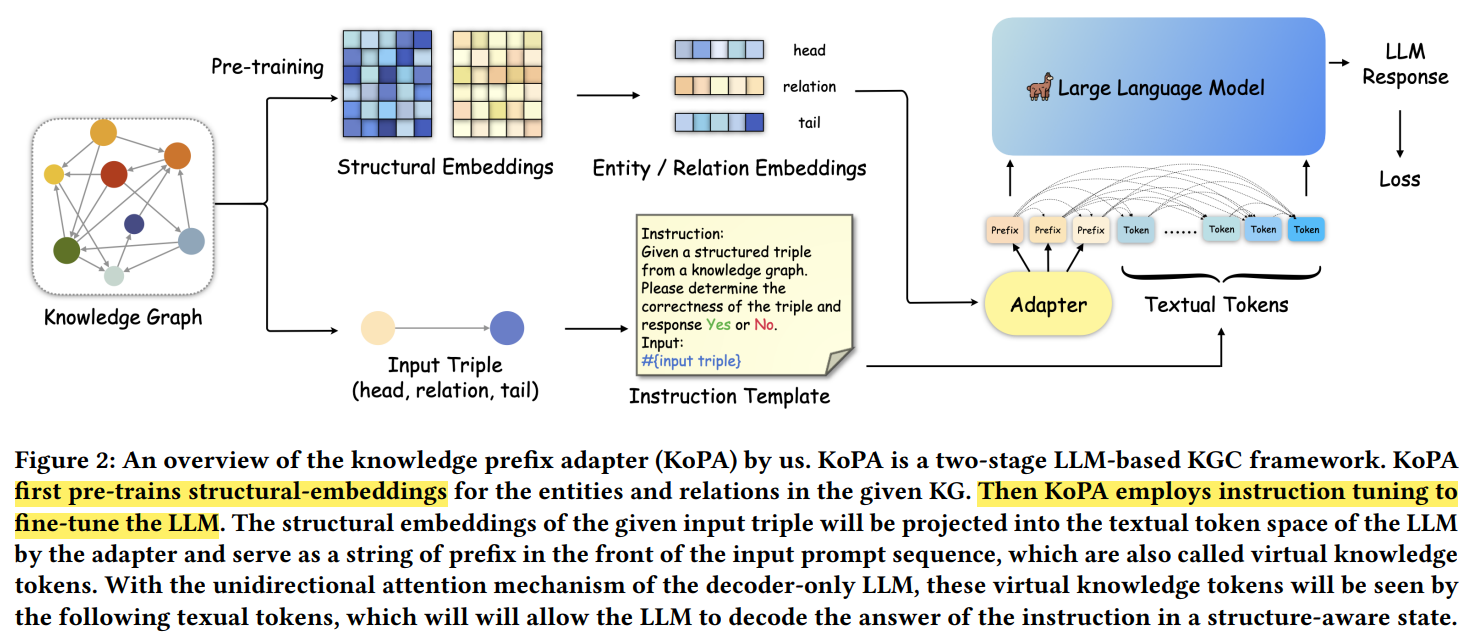
- Step 1: we extract the structural information of entities and relations from the KG through structural embedding pre-training
- Step 2: Then, we inject this structural information through a structural prefix adapter into the input sequence $S$.
- Step 3: LLM $M$ is the further tuned with structural-injected sequence.
Step 1: Structural embedding pre-training
- For each entity $𝑒 ∈ E$ and each relation $𝑟 ∈ R$, we learn a structural embedding $𝒆 ∈ R^{d_e}$, $𝒓 ∈ R^{d_r}$ respectively, where $𝑑_𝑒, 𝑑_𝑟$ are the embedding dimensions.
- We further adapt them into the textual representation space of LLMs
- We define a score function $F (ℎ, 𝑟, 𝑡)$ to measure the plausibility of the triple $(ℎ, 𝑟, 𝑡)$
- We adopt the self-supervised pre-training objective by negative sampling:
where $\gamma$ is the margin, $\sigma$ is the sigmoid activation function and $(h’_i, r’_i, t’_i),\quad (i = 1, 2, \ldots, K)$ are 𝐾 negative samples of (ℎ, 𝑟, 𝑡). The weight $p_i$ is the self-adversarial weights
- By minimizing the pre-training loss, the KG structural information such as subgraph structure and relational patterns is captured in the embeddings
Step 2: Knowledge prefix adapter
- After learning the structural embedding, we need to project them into the same textual token representation space of $M$, using knowledge prefix adapter $P$ (usually a simple projection layer)
where $K$ is the knowledge token, (𝒉, 𝒓, 𝒕) are the embeddings
- Hence, the input sequence:
Step 3: Fine tuning with $S_{kpa}$
- Finally, we froze the pre-trained structural embeddings and train the adapter to learn the mapping from structural knowledge toward textual representation
- LLM is further fine-tuned with $S_{𝑘𝑝𝑎}$
Complexity Analysis
KoPA makes the length of the prompt more refined, as the length of virtual tokens generated by the structural prefix adapter is fixed to 3 for head/relation/tail respectively

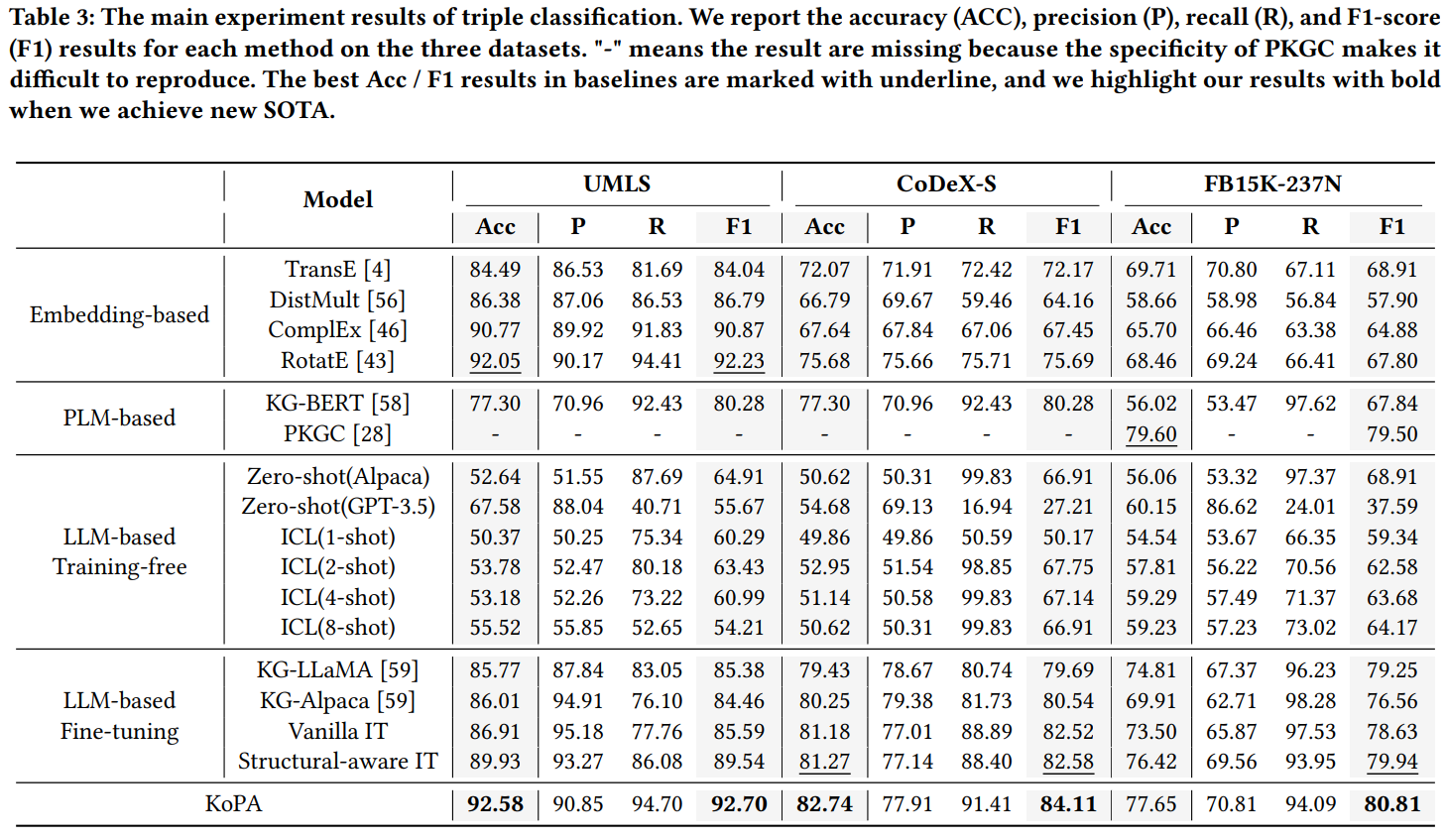
Results
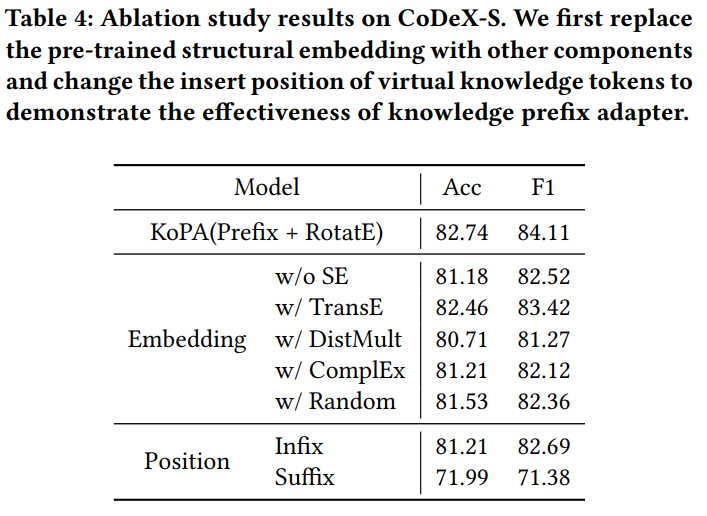
Ablation study
Note that putting the virtual knowledge tokens generated by the adapter in the middle (infix) or in the last (suffix) of the input sequence will also decrease the performance.
- We believe because of the decoder-only architectures with unidirectional self-attention
- Putting the token in front of the sequence make the model pay more attention to the structural information
Reference
- Zhang et al. “Making Large Language Models Perform Better in Knowledge Graph Completion”, arXiv preprint arXiv:2310.06671 (2023).