
NEFTune: Noisy Embedding Instruction Fine Tuning
Published:
This paper proposes NEFTune, a simple trick by adding noise to embedding vectors during training which improve the outcome of instruction fine-tuning by large margin. If you are using SFT trainier by huggingface, you can use this trick by simply adding one line of code!
Abstract
- The author proposes NEFTune, a simple trick by adding noise to embedding vectors during training which improve the outcome of instruction fine-tuning by large margin
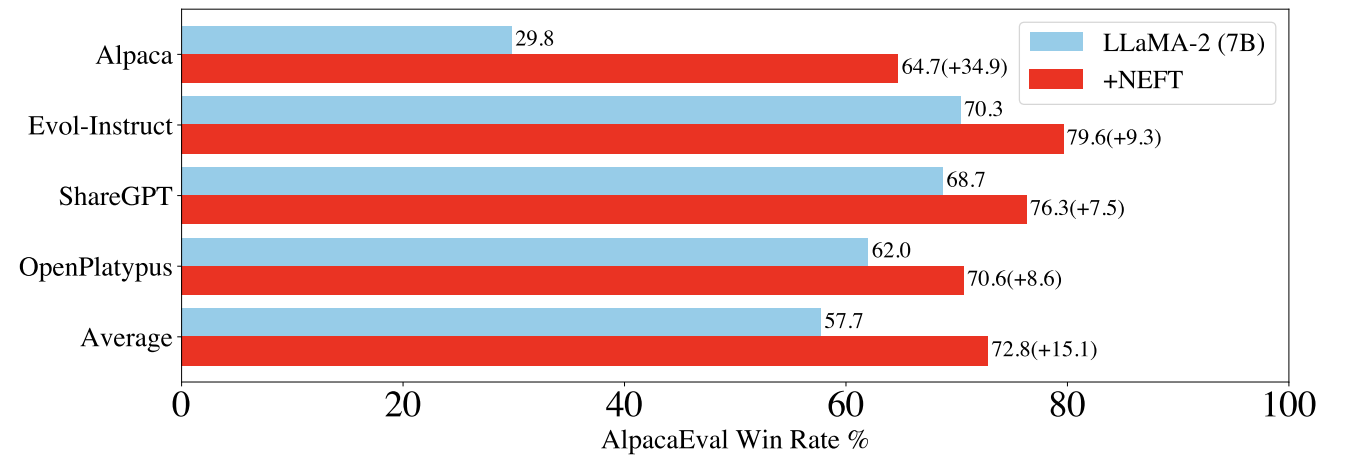
- This performance gain is as shown below:
Methodology
- During fine-tuning, pairs of instruction and responses are sampled, in the form of text
- The text are then tokenized, then turned into embedding vectors.
- These embeddings are then added with random noise sampled from uniform distribution
- The noise are then scaled with $\frac{\alpha}{\sqrt {Ld}}$ , where $\alpha$ is a tunable parameter, $L$ is the sequence length, $d$ is the embedding dimension
- Details:

Results
- Most of the experiments are conducted using 7B parameters of LLMs, including LLaMa-1, LLaMa-2 and OPT-6.7B
Conversational ability
- NEFTune improves conversational and answer quality, as measured via AlpacaEval
Further improvement on chat models
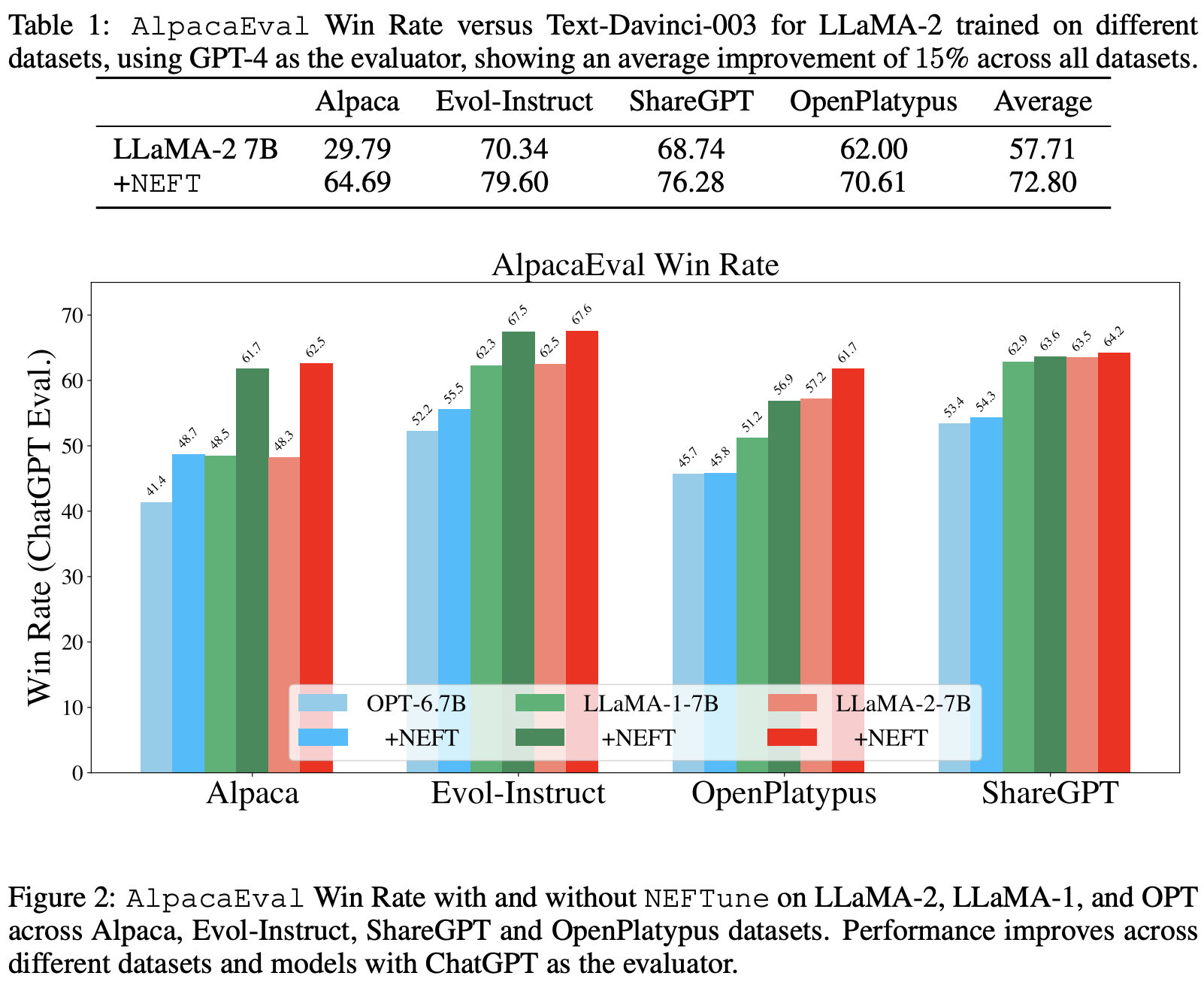
- NEFTune can further improve chat models.
- LLaMA-2-Chat (7B) is a extensively tuned model, with multiple rounds of RLHF.
- Further tuning LLaMA-2 Chat (7B) on Evol-Instruct gives another 3% boosts
- Furthermore, with NEFTune, we see a sizable, additional performance increase of 10%

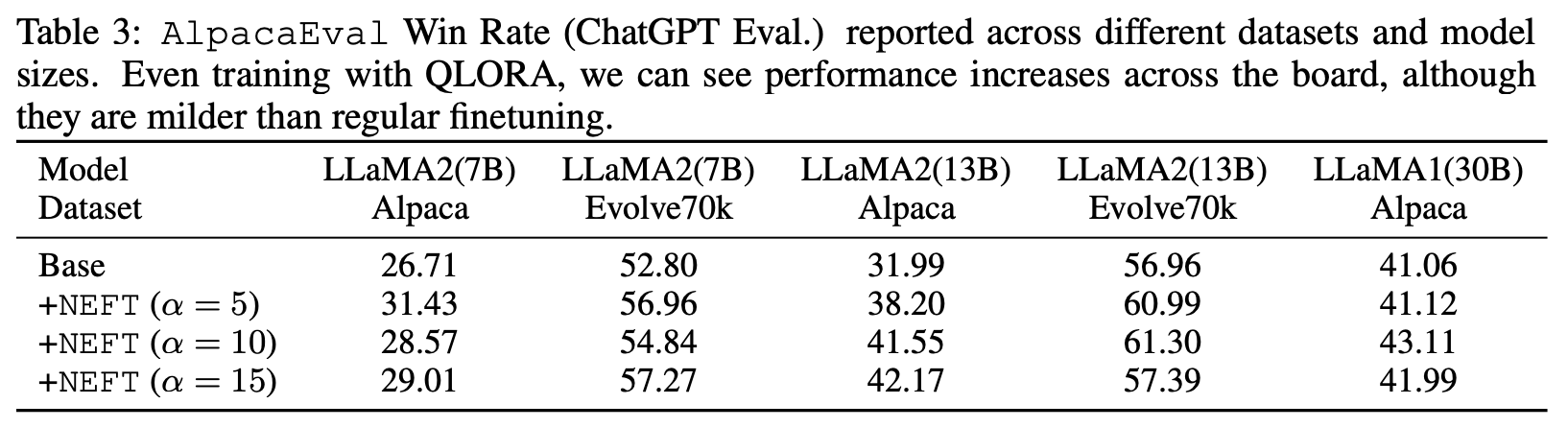
- NEFTune works with QLORA
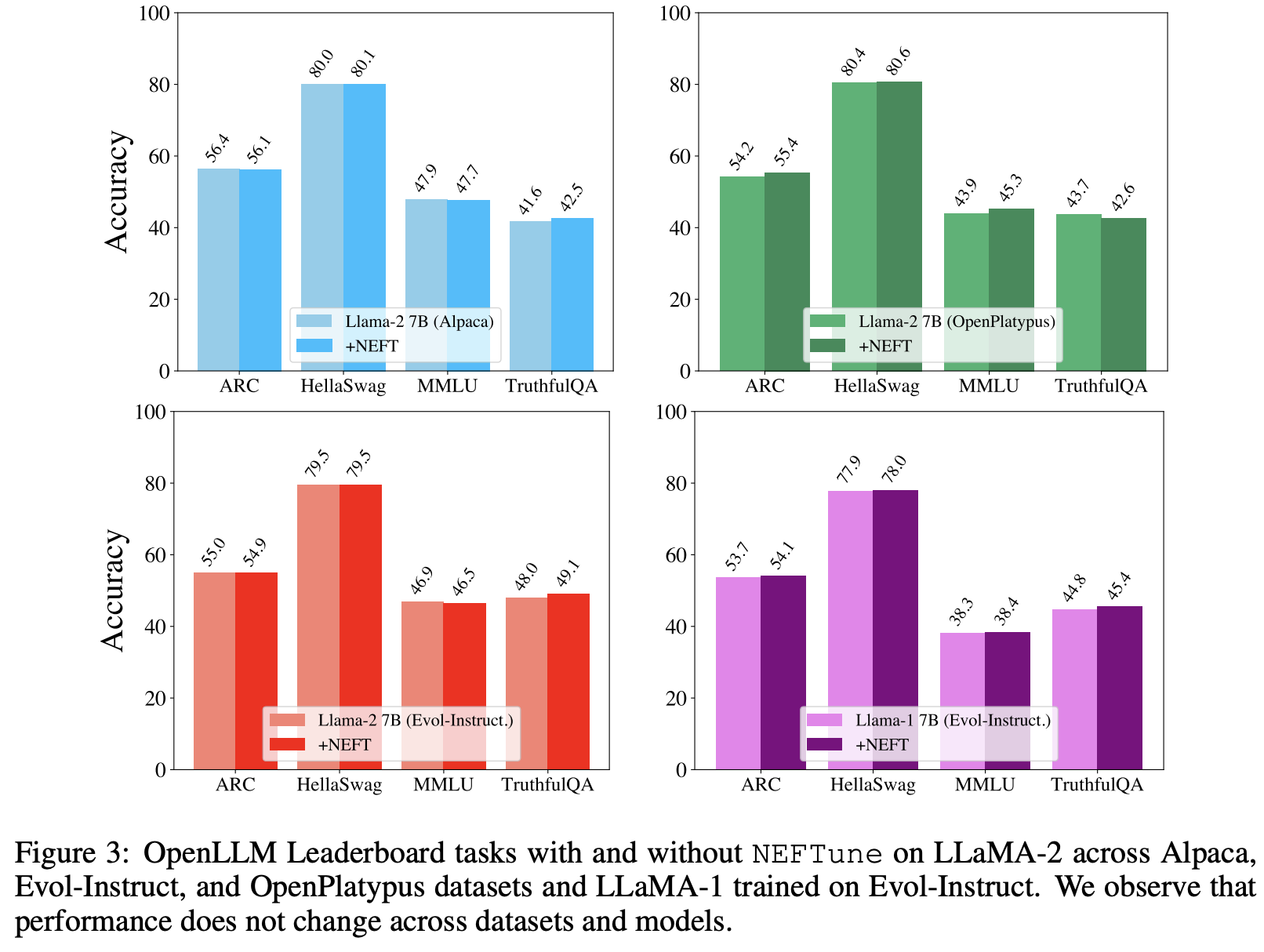
Does NEFTune sacrifices performance on other tasks to improve conversational ability?
- Figure below shows that NEFTune preserves model capabilities on other tasks
Reference
- Jain et al. “NEFTune: Noisy Embedding Instruction Fine Tuning, arXiv preprint arXiv:2310.05914 (2023)
Link
Appendix
To use it with SFT Trainer by huggingface
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("imdb", split="train")
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
neftune_noise_alpha=5,
)
trainer.train()
More details from link.
Detail implementation by huggingface SFT trainer:
def neftune_post_forward_hook(module, input, output):
"""
Implements the NEFTune forward pass for the model using forward hooks. Note this works only for
torch.nn.Embedding layers. This method is slightly adapted from the original source code
that can be found here: https://github.com/neelsjain/NEFTune
Simply add it to your model as follows:
```python
model = ...
model.embed_tokens.neftune_noise_alpha = 0.1
model.embed_tokens.register_forward_hook(neftune_post_forward_hook)
```
Args:
module (`torch.nn.Module`):
The embedding module where the hook is attached. Note that you need to set
`module.neftune_noise_alpha` to the desired noise alpha value.
input (`torch.Tensor`):
The input tensor to the model.
output (`torch.Tensor`):
The output tensor of the model (i.e. the embeddings).
"""
if module.training:
dims = torch.tensor(output.size(1) * output.size(2))
mag_norm = module.neftune_noise_alpha / torch.sqrt(dims)
output = output + torch.zeros_like(output).uniform_(-mag_norm, mag_norm)
return output